This Blog is Written in Clojure!
At last! A piece of software I can be proud of. Well, almost - there are a few bugs.
I'm writing this post to introduce the next incarnation of Logic Memory Center, a full stack blog written in the beautiful Clojure language.
Breaking up with WordPress
I've have been dissatisfied with WordPress for a while. While I wrestled it almost into what I wanted, plugins changed, themes got updated, it was never quite right. Even after I got it to the stage where I was reasonably happy with the workflow, things constantly broke. Even worse than that, I got a message on LinkedIn that my blog got hacked at some point due to me missing some security updated on Jetpack, and that my site was part of some botnet.
Put simply, WordPress is a hot mess. It was time for a change.
Our Savior, Emacs
I use Emacs a lot. Doom Emacs, specifically, has allowed me to pretty much create my perfect coding environment.
As I try to strive for a pretty integrated workflow, having to quit Emacs to type up a blog was leaving me wanting. But even more than that, I had to leave Org Mode.
Org Mode
If you take a look at the Emacs subreddit, people are recently flocking to the editor just to use one of its killer apps, Org mode. I talked about it in my previous Emacs blog post, but org is a pretty incredible piece of software.
Org is my writing tool, my markup language, my jupyter notebook, my todos, and most recently, my note-taking app with org-roam. If I am writing a blog post on programming, it makes so much more sense to have the blog actually execute the code and inline the results. What about \(\LaTeX\)?Wouldn't it be nice to have my post solve some symbolic code and inline the tex results? That just isn't really achievable with WordPress.
So, I had a plan.
The Plan
I have recently been diving headfirst into Clojure, a lisp that runs on the JVM. It is beautifully functional and meticulously designed. I'm not replacing my scientific computing Julia workflow, but I wanted a replacement for a more general purpose language, for lack of a better term. Julia could certainly do what I want, but Clojure is attractive to me for two reasons.
- I love lisps, they tend to make me think pretty differently about problems
- There exists a Clojure to JavaScript compiler called ClojureScript
I've been purposely avoiding web development because of the nightmare that is JavaScript. I heard of alternatives like TypeScript and the like, but I wasn't really interested in learning JS dialects. CLJS, on the other hand, is like a whole new language. It's pretty much just Clojure. That implies that I can write frontend and backend software in Clojure and have a seamless experience as well as not having to worry so much about data formatting in the API calls.
And that's where the tooling comes in. Emacs' Clojure support is god-tier, and that doesn't stop at just backend. Coupled with a piece of software called Figwheel, I can have Emacs open and live code both the frontend and backend software simultaneously. It feels magical having all the tools right where you need them and having instant feedback to everything.
So, to foray into web development, I decided to write a full-stack Clojure single page application to replace my blog. I came in pretty much knowing nothing about web development, so I thought the task was just at the right difficulty to learn how things generally worked.
Caveat Emptor
There are a few excellent tools that do what I am trying to do - namely, Firn and Cryogen. The first is an org to blog setup and the second is a markdown to blog. What I want is kinda in-between. I still want the ability to write posts in markdown. Additionally, I just wanted a project to work on, even though some of the work has already been done before. Additionally additionally, I didn't want a static site. I plan on playing around in CLJS more and I wanted the site to be able to integrate any future projects I work on that don't fit into the "static site" narrative.
Project Structure
So the plan is to start with how the posts will be written. From org mode, I
have pretty much the entire feature set of Markdown exposed, as well as all the
other features I mentioned before. Namely, it gives me tight integration with \(\LaTeX\) and executing code blocks with emacs-jupyter. The backend is going to have to ingest some form of the blog post, and while I could try to parse the org AST, as I mentioned, I thought I may want to write posts in Markdown at some point. Additionally, all of my old blog posts from WordPress have to be imported somehow.
There are numerous static site generation tools and there seems to be a commonality in that they usually have the posts themselves written in Markdown. One of the more full featured static site tools, Hugo, seems pretty popular. And as such, there is an export tool that grabs all the posts and content from a WordPress site into a Markdown format that works for Hugo.
So, my plan was to have the backend parse Markdown to fill out the blog post content.
Frontend
I actually started work first on the frontend. There are a ton of ClojureScript frontend options, but I went with reagent, a library that provides wrappers for React. React seems cool, so why not? Also if I ever want to do any app stuff, there is always React Native, of which there are ClojureScript wrappers for. So I scaffold-ed a project that had a reagent frontend integrated with Figwheel to provide the hot code reloading.
I then threw together some structure using Bootstrap. As I express all the divs and such with Clojure data (Hiccup), reagent creates React components for all the things that need them. Take the following Bootstrap html:
<div class="jumbotron text-center">
<h1>My First Bootstrap Page</h1>
<p>Resize this responsive page to see the effect!</p>
</div>
<div class="container">
<div class="row">
<div class="col-sm-4">
<h3>Column 1</h3>
<p>Lorem ipsum dolor..</p>
</div>
<div class="col-sm-4">
<h3>Column 2</h3>
<p>Lorem ipsum dolor..</p>
</div>
<div class="col-sm-4">
<h3>Column 3</h3>
<p>Lorem ipsum dolor..</p>
</div>
</div>
</div>I can recreate the same thing with reagent using hiccup like this:
(defn my-page []
(list ; two different divs
[:div {:class "jumbotron text-center"}
[:h1 "My First Bootstrap Page"]
[:p "Resize this responsive page to see the effect!"]]
[:div.container ; I can use the dot syntax for tag classes
[:div.row ; But I really only used them for short class names
[:div {:class "col-sm-4"}
[:h3 "Column 1"]
[:p "Lorem ipsum dolor.."]]
[:div {:class "col-sm-4"}
[:h3 "Column 2"]
[:p "Lorem ipsum dolor.."]]
[:div {:class "col-sm-4"}
[:h3 "Column 3"]
[:p "Lorem ipsum dolor.."]]]]))And because its just clojure data, I could extract out the repeating column code to make it even simpler:
(defn my-col [title content]
[:div {:class "col-sm-4"}
[:h3 title]
[:p content]])
(def content "Lorem ipsum dolor..")
(defn my-page []
(list
[:div {:class "jumbotron text-center"}
[:h1 "My First Bootstrap Page"]
[:p "Resize this responsive page to see the effect!"]]
[:div.container
[:div.row
(for [i (range 1 4)]
(my-col (str "Column " i) content))]]))Pretty nice, right?
Once there was some semblance of data containers, I started thinking about the APIs to get the post data to the frontend. Using cljs-http, I set up what would be the RESTfull calls to the backend; I expected to get the rendered Markup as just a big HTML string.
To do this, I set up an atom to store all post content, that gets lazily loaded when the content is requested.
(defonce !posts-body (atom nil))
(defn get-post-body [id]
(when-not (get @!posts-body id)
(go (let [body (:body (<! (http/get (str "/api/post-body/" id)
{:accept "application/edn"})))]
(swap! !posts-body assoc id body)))))As the backend will be written in Clojure, I can just pass application/edn directly to the frontend. Also, notice the GET is asynchronous, which then hooks into reagent such that the React element gets re-rendered once that data shows up.
Also this atom is from reagent, which works with react to hook up all of the rendering bologna with async events. As I use the contents of @post-body in a form that gets passed to the main render function, React will know to re-render it once that GET completes and populates the atom with new data.
As the site is an SPA, I needed to set up a client-side router so it appears that the user is navigating, even though reagent is just redrawing the page. I use a library called reitit to set this up, as it offers the same software for the backend and frontend, which will be nice down the road.
(def routes
[["/"
{:name ::homepage
:view home-body
:controllers [{:start (fn [_]
(root-route-callback))}]}]
["/post/:id"
{:name ::post
:view blog-body
:parameters {:path {:id string?}}
:controllers [{:parameters {:path [:id]}
:start (fn [{{id :id} :path}]
(post-route-callback id)
(.scrollTo js/window 0 0))}]}]]
...)These routes set up what GETs need to be called for the different routes (through the callbacks) and what React components to actually render (through the :view tag).
Backend
For the backend, I'm using Ring + Jetty to actually serve the content. Simply enough, I setup the location of the static content, the compiled JS output and the functionality for the various API calls.
So this would have been enough but I hit a snag.
The markdown library I was using, markdown-clj didn't support all the features I wanted. Really, I wanted all the features Hugo supports. This includes tables from GFM, latex, shortcodes, heading refs, footnotes, citations, blockquotes, etc. There are a few other clojure-markdown libraries, but none of them were 100% of what I wanted. Most of them didn't allow for much customization if at all, which makes implementing the more complex markdown extensions difficult.
You know what that means? I decided I had to write a Markdown parser.
Cybermonday
So Hugo used to use a flavor of Markdown called Blackfriday. Ox-Hugo, the org-exporter for Hugo used this format. So, my plan was replace rendering markdown to a string of HTML, parse the Markdown directly into the Hiccup data structure that reagent wanted. This means that I can postprocess the document in Clojure painlessly.
I first tried to write a parser using instaparse, a Clojure library that builds parsers from EBNF and ABNF context-free grammars. I probably spent a week or so, with moderate success. However, the edge cases were getting incredibly difficult to figure out. But really I was fighting the fact that Markdown isn't context free. I needed another option.
So then I found a Java library called Flexmark. The goal of this software is just to create HTML from Markdown, but as it is a parser after all, it has to represent the markdown as an AST at some point. As Clojure runs on the JVM and has excellent interoptability with Java, I can intercept that java AST and perform a tree-transformation to generate the Hiccup that we want.
That was about a month of work, but the result is pretty nice. Flexmark is very flexible, so it can be configured to support all sorts of weird Markdown features. The hardest part was the fact that Markdown can have arbitrary HTML inside it. I used Hickory to parse large HTML blocks, but for the inline stuff, I had to write a naïve HTML parser. It only works on tags that have proper closed tags, and a few other edge cases, but it does work for simple stuff like inline style and html entities.
Once I polish it up a little bit, I will probably publish the library, as any Clojure software that uses hiccup could use it. I'm pretty proud of it.
Putting the pieces together
So the backend parses the posts into hiccup and serves the data to the frontend and the frontend generates all the react components to draw what you are currently reading.
The last few steps were styling with some CSS, implementing a little search feature, and making the UX a bit cleaner. All in all, I am really happy with how it turned out. Best of all, I didn't have to write a single line of JS! Its all Clojure, which means it's all just data.
I'll publish the source soon for this - I'll clean it up to make it a bit more presentable. I do want to note that this isn't meant to be really used by others - there isn't any templating or anything. It was just meant to be a personal project for me to learn full stack clojure. However, once I post it, anyone will be of course free to use it.
Importing Stuff From WordPress
To test to see if I was successful, I ran my WordPress blog though a tool that transformed everything to Hugo-compatible markdown.
A few of my old blog posts were written in Org actually, pushed to WP with some tool that I can't remember. For those posts (they are the ones that were written for school reports and were also rendered to \(\LaTeX\), I just ran them through ox-hugo. I had to fix a couple of things for the WP to Hugo stage as it wasn't quite 100%, but all it all it seemed to work!
So I can finally uninstall WordPress!
Some Examples
So just to show off a couple of cool features, specifically from Org:
Code Blocks
So here is emacs-jupyter inlining the results:
using Plots
Base.@kwdef mutable struct Lorenz
dt::Float64 = 0.02
σ::Float64 = 10
ρ::Float64 = 28
β::Float64 = 8/3
x::Float64 = 1
y::Float64 = 1
z::Float64 = 1
end
function step!(l::Lorenz)
dx = l.σ * (l.y - l.x); l.x += l.dt * dx
dy = l.x * (l.ρ - l.z) - l.y; l.y += l.dt * dy
dz = l.x * l.y - l.β * l.z; l.z += l.dt * dz
end
attractor = Lorenz()
plt = plot3d(
1,
xlim = (-30, 30),
ylim = (-30, 30),
zlim = (0, 60),
title = "Lorenz Attractor",
marker = 2,
)
anim = @animate for i=1:1500
step!(attractor)
push!(plt, attractor.x, attractor.y, attractor.z)
end every 10
gif(anim,"lorenz.gif")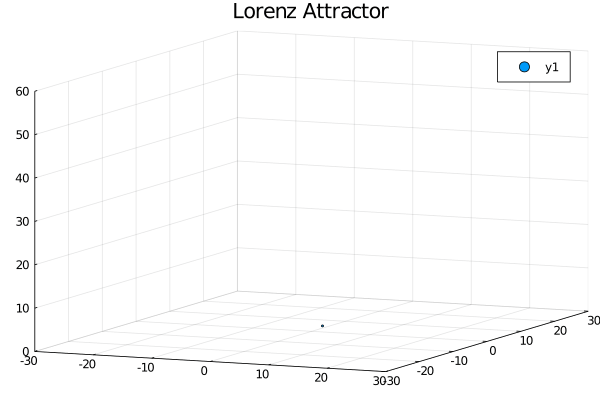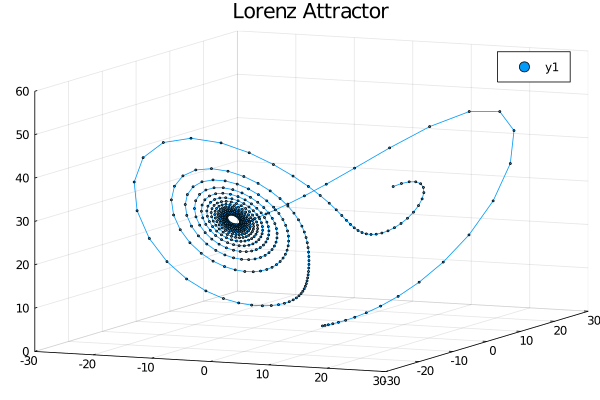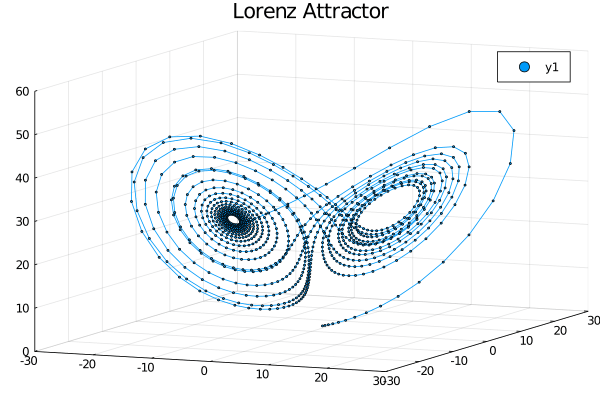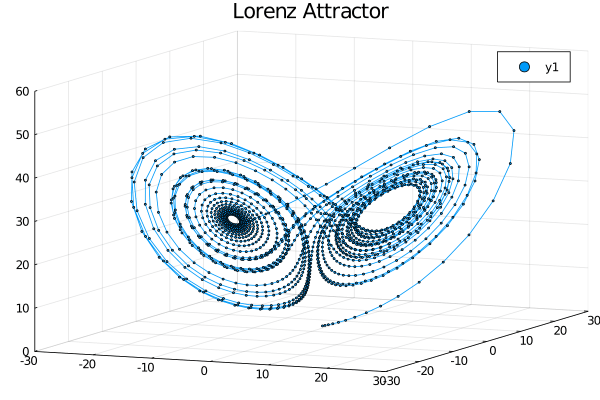
It even works for things that the more jupyter-y MIME types
# Exporting render-able latex from python
from sympy import *
x = symbols('x')
Integral(sqrt(1/x),x)# Exporting a table from python
[[1,2,3], [4,5,6], [7,8,9]]| 1 | 2 | 3 |
|---|---|---|
| 4 | 5 | 6 |
| 7 | 8 | 9 |
Citations and Footnotes
I can add citations from my main bibtex file like this rupakula20_limit_scan_angle_phased_array
Next Steps
I will be adding more features soon as I have a couple of ideas on how to improve things.
Right now, you will be served a light or dark mode depending on what your OS reports as its "color preference". Sometimes this doesn't work, or the user might want to switch, so I need to add a button that toggles the mode, but that is proving to be a little tricky.
Thanks for reading!